Beam Search
When generating new sentences for the test data, we used to take the word with the highest likelihood at each time as the correct answer and use it as input in the next step. However, what we really want to do is to generate a sentence that has the highest likelihood for the entire sentence. Therefore, rather than just short-sightedly adopting the words with the highest probability, we need to evaluate the situation a bit more broadly.
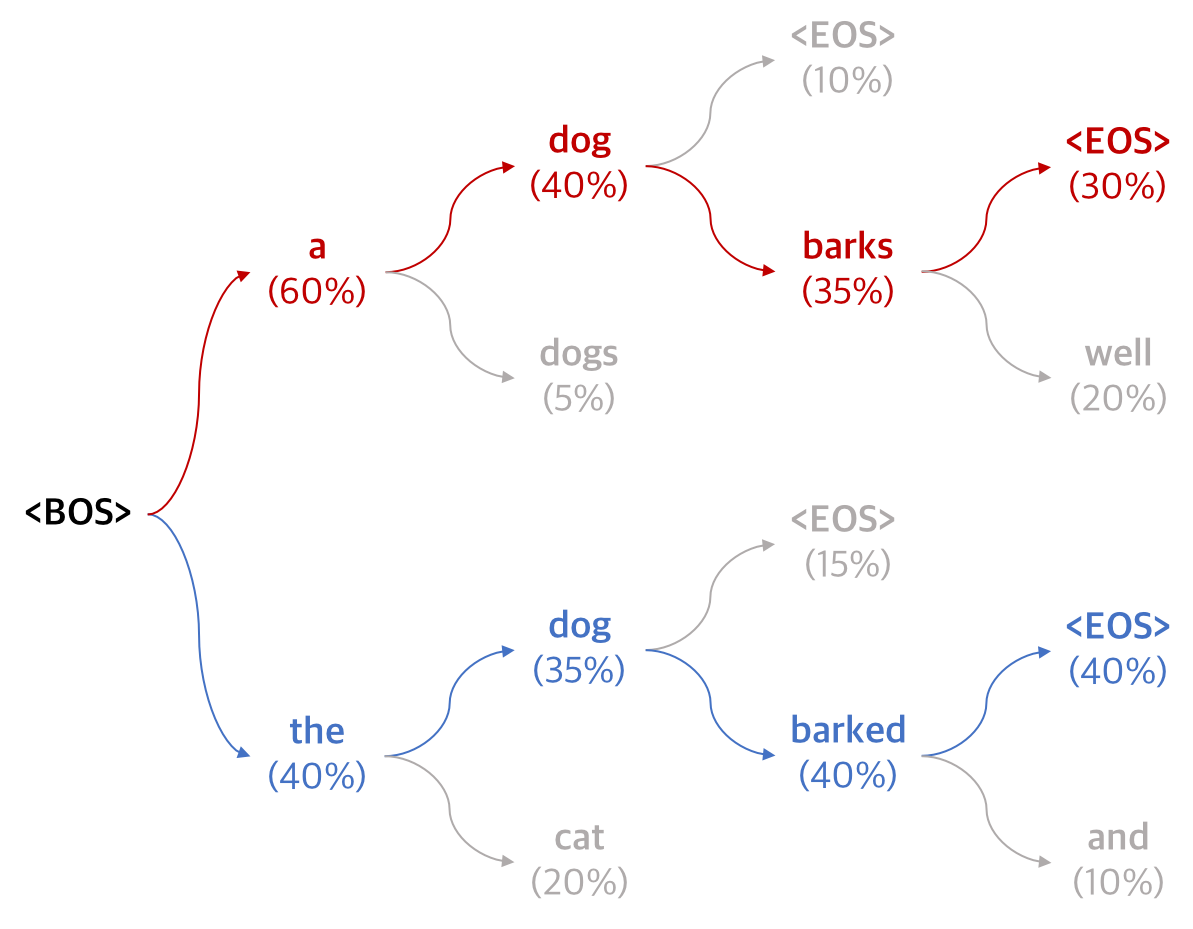
Beam Search performs selection by retaining a certain number of K sentences with high scores (e.g., log likelihood) at each time point.
The following figure shows the process of outputting words based on the output word and score (in % for simplicity) at each step when K=2, while retaining the top two paths.
By exploring words other than the highest scoring word (red) at each step, we are able to obtain a path with a higher cumulative score (blue) in the end.
Below is an example implementation of a class that performs decoding in Beam Search.
For simplicity of implementation, input is assumed to be a single sample (batch_size=1), and mini-batches (batch_size>1) are not supported.
class BeamEncoderDecoder(EncoderDecoder):
"""
Class for decoding with Beam Search
"""
def __init__(self, input_size, output_size, hidden_size, beam_size=4):
"""
:param input_size: int, Number of input language vocabulary
:param output_size: int, Number of output language vocabulary
:param hidden_size: int, Number of hidden layer units
:param beam_size: int, Number of beams
"""
super(BeamEncoderDecoder, self).__init__(input_size, output_size, hidden_size)
self.beam_size = beam_size
def forward(self, batch_X, lengths_X, max_length):
"""
:param batch_X: tensor, Input series batch, size=(max_length, batch_size)
:param lengths_X: list, Sentence length for each sample in the batch of input series
:param max_length: int, Decoder maximum sentence length
:return decoder_outputs: list, Decoder output for each beam
:return finished_scores: list of float, Scores for each beam
"""
_, encoder_hidden = self.encoder(batch_X, lengths_X)
# Define input of decoder and initial state of hidden layer
decoder_input = torch.tensor([BOS], dtype=torch.long, device=device)
decoder_input = decoder_input.unsqueeze(0)
decoder_hidden = encoder_hidden
# Repeat as many times as beam_size
decoder_input = decoder_input.expand(1, beam_size)
decoder_hidden = decoder_hidden.expand(1, beam_size, -1).contiguous()
k = beam_size
finished_beams = []
finished_scores = []
prev_probs = torch.zeros(beam_size, 1, dtype=torch.float, device=device) # Keep the log-likelihood of each beam at the previous time\
output_size = self.decoder.output_size
# Processed at each time
for t in range(max_length):
# decoder_input: (1, k)
decoder_output, decoder_hidden = self.decoder(decoder_input[-1:], decoder_hidden)
# decoder_output: (1, k, output_size)
# decoder_hidden: (1, k, hidden_size)
decoder_output_t = decoder_output[-1] # (k, output_size)
log_probs = prev_probs + F.log_softmax(decoder_output_t, dim=-1) # (k, output_size)
scores = log_probs # Score the log-likelihood
# Get the highest scoring beams and their words
flat_scores = scores.view(-1) # (k*output_size,)
if t == 0:
flat_scores = flat_scores[:output_size] # Exclude repetition of the same value in the second half when t=0
top_vs, top_is = flat_scores.data.topk(k)
beam_indices = top_is // output_size # (k,)
word_indices = top_is % output_size # (k,)
# Update beam
_next_beam_indices = []
_next_word_indices = []
for b, w in zip(beam_indices, word_indices):
if w.item() == EOS: # If EOS is reached, that beam is updated and terminated
k -= 1
beam = torch.cat([decoder_input.t()[b], w.view(1,)]) # (t+2,)
score = scores[b, w].item()
finished_beams.append(beam)
finished_scores.append(score)
else: # Otherwise, update beam
_next_beam_indices.append(b)
_next_word_indices.append(w)
if k == 0:
break
# Convert to tensorn
next_beam_indices = torch.tensor(_next_beam_indices, device=device)
next_word_indices = torch.tensor(_next_word_indices, device=device)
# Update Decoder input at next time
decoder_input = torch.index_select(
decoder_input, dim=-1, index=next_beam_indices)
decoder_input = torch.cat(
[decoder_input, next_word_indices.unsqueeze(0)], dim=0)
# Update hidden layer of Decoder at next time
decoder_hidden = torch.index_select(
decoder_hidden, dim=1, index=next_beam_indices)
# Update log-likelihood for each beam
flat_probs = log_probs.view(-1) # (k*output_size,)
next_indices = (next_beam_indices + 1) * next_word_indices
prev_probs = torch.index_select(
flat_probs, dim=0, index=next_indices).unsqueeze(1) # (k, 1)
# Shape data when all beams are complete
decoder_outputs = [[idx.item() for idx in beam[1:-1]] for beam in finished_beams]
return decoder_outputs, finished_scores
# Loading trained models
beam_size = 3
beam_model = BeamEncoderDecoder(**model_args, beam_size=beam_size).to(device)
beam_model.load_state_dict(ckpt)
beam_model.eval()BeamEncoderDecoder( (encoder): Encoder( (embedding): Embedding(2698, 256, padding_idx=0) (gru): GRU(256, 256) ) (decoder): Decoder( (embedding): Embedding(3051, 256, padding_idx=0) (gru): GRU(256, 256) (out): Linear(in_features=256, out_features=3051, bias=True) ) )
test_dataloader = DataLoader(test_X, test_Y, batch_size=1, shuffle=False)# generation
batch_X, batch_Y, lengths_X = next(test_dataloader)
sentence_X = ' '.join(ids_to_sentence(vocab_X, batch_X.data.cpu().numpy()[:-1, 0]))
sentence_Y = ' '.join(ids_to_sentence(vocab_Y, batch_Y.data.cpu().numpy()[:-1, 0]))
print('src: {}'.format(sentence_X))
print('tgt: {}'.format(sentence_Y))
# Ordinary decode
output = model(batch_X, lengths_X, max_length=20)
output = output.max(dim=-1)[1].view(-1).data.cpu().numpy().tolist()
output_sentence = ' '.join(ids_to_sentence(vocab_Y, trim_eos(output)))
print('out: {}'.format(output_sentence))
# beam decode
outputs, scores = beam_model(batch_X, lengths_X, max_length=20)
# Sort by score in order of best to worst
outputs, scores = zip(*sorted(zip(outputs, scores), key=lambda x: -x[1]))
for o, output in enumerate(outputs):
output_sentence = ' '.join(ids_to_sentence(vocab_Y, output))
print('out{}: {}'.format(o+1, output_sentence)) src: show your own business . tgt: 自分 の 事 を しろ 。 out: 仕事 を <UNK> し な い 。 out1: 仕事 を <UNK> し な い 。 out2: 仕事 を <UNK> し な 。 out3: 仕事 を <UNK> し な い 。 /usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:55: UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor').